Word Salad Sifter
A Chrome Extension integrating Google Docs and Anthropic's API to capture highlighted, job-listing text and transform it into structured information, which is then stored in a user's Google Docs. The system uses Anthropic's API to parse job descriptions and extract key attributes relevant to resume tailoring.
Overview
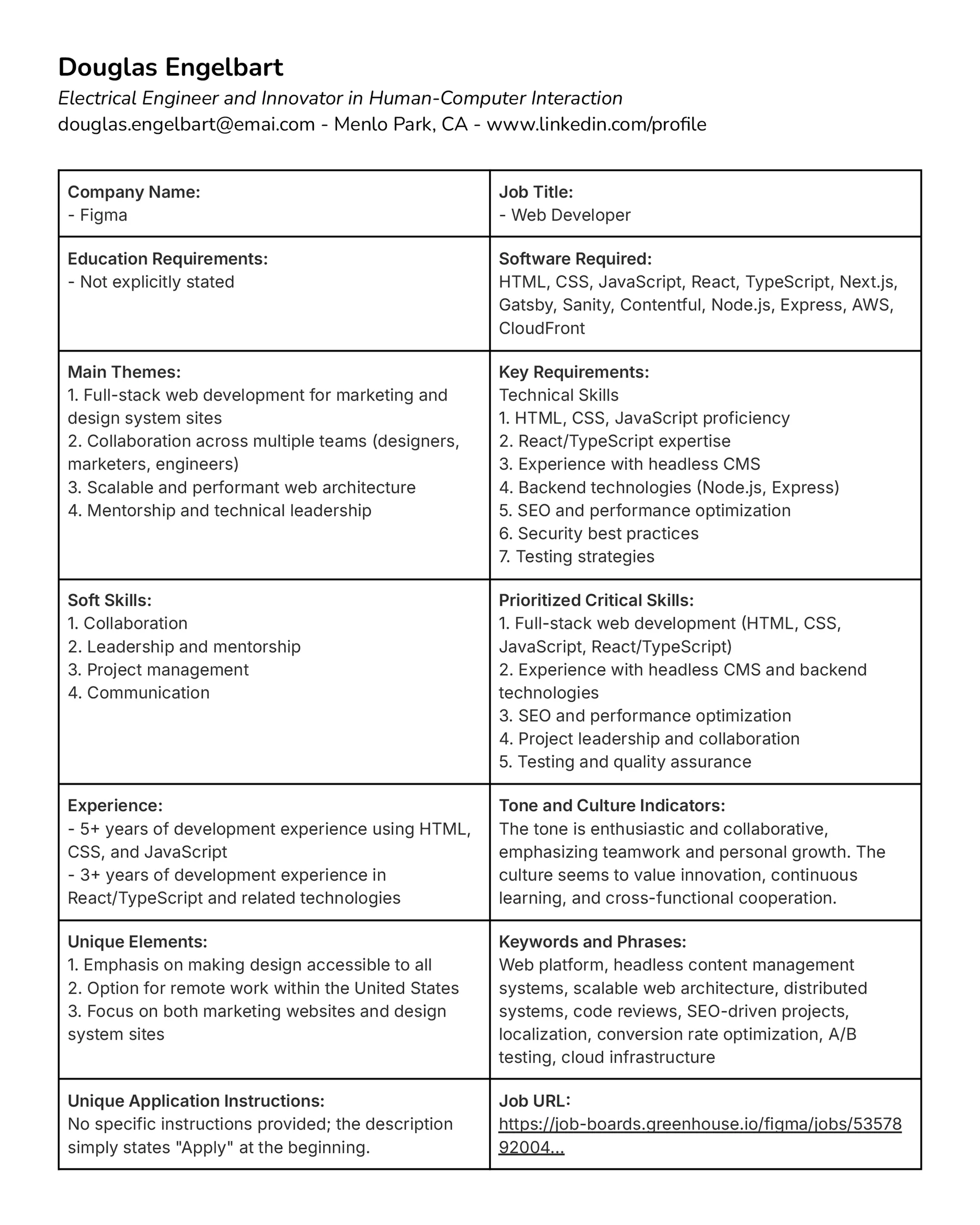
Job postings are typically long, loosely structured documents that contain useful signals, filler text, and boilerplate language. For applicants intent on tailoring resumes and cover letters, it's burdensome to identify what information actually matters.
Word Salad Sifter focuses on extracting the useful signals. The extension allows users to highlight a job description directly in the browser and convert it into a structured reference table within a working resume document.
The goal is not to generate application materials automatically, but to provide a structured framework that helps applicants craft their own targeted, human responses (see example below).
System Outline
This system connects three primary services:
1. Browser capture
- Captures user-highlighted text from job listings
2. Processing
- Anthropic API parses the job description
- Response is normalized into structured schema
3. Document Generation
- Google OAuth for user authentication
- Google Drive API duplicates the resume document
- Google Docs API allows insertion of structured output
The result is a consistent reference table embedded directly in a working resume document.
Architecture
Word Salad Sifter consists of three interacting component-layers:
Chrome Extension Layer
- Handles user interaction, text capture, and UI feedback.
- Ensures valid API key and login exists.
The extension integrates two external services: Anthropic for text parsing and Google APIs for document creation. The login flow validates the user's API key and establishes a Google OAuth session before any processing is allowed to occur.
Processing Layer
- Anthropic's API interprets the job description and extracts structured attributes such as required skills, experience expectations, and tone indicators.
Document Integration Layer
- Google APIs duplicate the user's resume and append structured information into a standardized table.
The parsing process converts raw job posting text into structured data through a multi-stage pipeline.
High-level flow: User highlights job posting
- → extension captures text
- → text sent to processing API
- → structured response returned
- → Google Docs updated with extracted information
Key Technical Decisions
Structured extraction instead of document generation
- Rather than using an LLM to generate full resumes or cover letters, the system extracts structured signals from the job posting. This preserves the applicant's voice while still surfacing the most relevant information.
Tabular normalization
- Job postings vary widely in structure. A consistent table format makes it easier to compare roles and quickly scan requirements.
Each processed job description is converted into a predictable set of attributes:
- Company name and job title
- Education requirements
- Required software knowledge
- Core job themes
- Key requirements
- Essential soft skills
- Prioritized critical skills
- Experience requirements
- Cultural indicators and tone
- Position's unique elements
- Critical keywords and phrases
- Special application instructions
- Source URL
Lightweight browser integration
- A Chrome extension was chosen instead of a standalone application so the system could operate directly on job boards without requiring copy-paste workflows.
Platform Considerations
Chrome extension architecture
Chrome extensions operate across separate execution contexts:
- background service worker
- UI surfaces (popups, side panels)
- content scripts
Communication between these contexts requires message passing. Temporary state must be explicitly preserved or it will be lost when UI components close.
To handle this, the extension uses Chrome's storage API to maintain session data across contexts.
Processing latency
LLM processing time varies based on text length and API latency. The extension provides feedback to the user with estimated completion time and processing status.